Text Books
T1 Ponniah P, “Data Warehousing Fundamentals”, Wiley Student Edition, 2012
T2 Kimball R, “The Data Warehouse Toolkit”, 3e, John Wiley, 2013

C.True: If the vendor's investments in new technologies can be leveraged, their customers do not have to solve these same problems. Buying the new package is to take the advantages of the lessons the vendor have learned in how to apply the new technologies.
D. True: In an operational system, users get information thru predefined screens and reports. In DW, users seek information thru ad-hoc queries.
E. False: Information in DW is accumulated over long periods and elaborately prepossessed
F. True: We may find that the system vendor suggests selecting parts of different schemas and constructing a pack and mix schema of your own. This is known as pragmatic approach, we need to understand of data loss through truncation and mapping. in this situation Metadata standard facilitate the interchange between system rather than describe a form of storage.
Question.8
Consider a retail store data cube with dimensions Product, Date, and Store, and the measure attribute Sales
a. Draw the lattice of cuboids for this data cube without considering hierarchies.
b. Suppose that the dimensional attributes have the following hierarchies defined. How many cuboids would the data cube contain for this set of hierarchies?
Question.9
Bitmap Index:
Bitmap indexes are used by DBMSs to accelerate decision support queries. The main advantage of the bitmap index is that complex logical selection operations can be done very quickly by minimizing the search space before low cost Boolean operations like OR, AND, and NOT, before moving on to primary source data.
A Bitmap index: consists of one bitmap for each value that an attribute can take.
We will illustrate our discussion with a simple example about stock trading. Let us see the following table on stocks traded at different stock exchanges and consider the last column (Exchange).
Example:

We notice that stocks are traded at two different stock exchanges at NASDAQ and at NYSE. Indeed, the attribute Exchange has two distinct attribute values. In addition, we see that our stock examples include 12 different stocks, which are uniquely identified by their record ID given in the first column.
Simple bitmap for Stocks and their corresponding trading values:
NASDAQ: (1 0 0 0 0 1 0 0 0 1 1 1)
NYSE: (0 1 1 1 1 0 1 1 1 0 0 0)
T1 Ponniah P, “Data Warehousing Fundamentals”, Wiley Student Edition, 2012
T2 Kimball R, “The Data Warehouse Toolkit”, 3e, John Wiley, 2013
Question.1
Match the following :
Answer:
Nonvolatile data
|
Read only
|
Dual data granularity
|
Details and summary
|
Dependent data mart
|
Data from main DW
|
Disparate data
|
Because of multiple sources
|
Decision support
|
Subject-oriented
|
Data staging
|
Workbench for data Integration
|
Data mining
|
Knowledge discovery
|
Meta data
|
Roadmap for users
|
Operational systems
|
Application flavor
|
Internal data
|
Private spreadsheets
|
Question.2
Classify metadata for following as Data Acquisition, Data Storage, or Information Delivery metadata.
1) Data Archival Rules
2) Predefined queries and reports
3) Source system from which data come
4) Information about last successful update
5) Types of aggregations
6) Information about data transformation rules
Answer:
1) Data Archival Rules : Data Storage
2) Predefined queries and reports : Information Delivery
3) Source system from which data come : Data Acquisition
4) Information about last successful update: Data Storage
5) Types of aggregations: Data Acquisition
6) Information about data transformation rules : Data Acquisition
Question.3
Provide short answers to the following :
a. How do you differentiate a Data Warehouse from an application database?
b. What is a conformed dimension?
c. Differentiate initial load, incremental load, and full refresh
d. How can MapReduce processing help DW?
e. What is the difference between WINDOW and GROUP BY clauses in SQL SELECT statements?
Answer:
A. Differentiate a Data Warehouse from an application database:
Database:
- It’s normally used for online transaction processing (OLTP) however it can be used for other purposes such as data warehousing. It records data from the user for history.
- Tables and joins are complex because they are generalized (for RDMS). This is done to reduce unnecessary data and save storage space.
- Optimized for write operation.
Data Warehouse:
- It’s normally used for used for Online Analytical Processing (OLAP). It reads the historical data for the Users for business decisions.
- Optimized for read operations.
- Tables and joins are simple since they are De-normalized. It is done to reduce the response time for analytical queries.
Answer:
B. Conformed dimension:
- A conformed dimension is a dimension that has exactly the same meaning and content when being referred from different fact tables.
- It can refer to multiple tables in multiple data marts within within a single organization.
- Example, Except for the primary dimension, two dimension tables are exactly the same, which are not considered to be conformed dimensions.
Answer:
C. Differentiate between initial load, full refresh and incremental load:
C. Differentiate between initial load, full refresh and incremental load:
Initial Load : It is the process of populating data warehousing tables for the very first time.
full refresh : When loading the data for the first time, all set records are loaded on a stretch based on the volume. It wipes and reloads all the contents of tables with fresh data.
Incremental Load : In this load we apply dynamic changes when needed in a specific period. The schedule is prescribed for each period (to get the latest record)
full refresh : When loading the data for the first time, all set records are loaded on a stretch based on the volume. It wipes and reloads all the contents of tables with fresh data.
Incremental Load : In this load we apply dynamic changes when needed in a specific period. The schedule is prescribed for each period (to get the latest record)
Answer:
D.
D.
MapReduce programming paradigm is very powerful and flexible, It has been widely used for parallel computing in data-intensive areas due to its good scalability.
How MapReduce processing help DW:
* MapReduce makes it easier to write a distributed computing program by providing
- inter-process communication
- fault-tolerance
- load balancing
- and task scheduling.
* MapReduce integration allows fully parallel, distributed jobs against your data with locality awareness[Batch processing].
* This reduces difficult programming work, for the user only has to create a configuration file with some lines of code to declare the dimensions and fact objects and necessary change functions.
* This reduces difficult programming work, for the user only has to create a configuration file with some lines of code to declare the dimensions and fact objects and necessary change functions.
Answer:
E. Difference between WINDOW and GROUP BY clauses in SQL SELECT statements:
E. Difference between WINDOW and GROUP BY clauses in SQL SELECT statements:
- Group by is an aggregate whereas over() is a window function.
- When a group by clause is used all the columns in the select list should either be in group by or should be in an aggregate function.
- While in over() clause, we don't have any such restriction. Aggregates or other functions can be calculated using over function along-with other columns in the select list.
Question.4
For following statements, indicate true or false with proper justification:
A. It is a good practice to drop the indexes before the initial load.
B. It is equally important to include unstructured data along with structured data in a data
Warehouse
C. Technical architecture consists of the vendor tools.
D. The importance of metadata is the same in a data warehouse as it is in an operational
system.
E. Backing up the data warehouse is not necessary because you can recover data from the source systems.
F. Metadata standards facilitate metadata interchange among tools.
Answer:
A. True: Index entry creation during mass load can be very time consuming. Therefore, to speed up load, drop the index before loading. You can rebuild or reproduce the index when the load is completed.
B. True: Both types of data are vital in the modern digital enterprise, but they must be managed differently. Because most of the business-relevant information originates in unstructured form.
B. True: Both types of data are vital in the modern digital enterprise, but they must be managed differently. Because most of the business-relevant information originates in unstructured form.
C.True: If the vendor's investments in new technologies can be leveraged, their customers do not have to solve these same problems. Buying the new package is to take the advantages of the lessons the vendor have learned in how to apply the new technologies.
D. True: In an operational system, users get information thru predefined screens and reports. In DW, users seek information thru ad-hoc queries.
E. False: Information in DW is accumulated over long periods and elaborately prepossessed
F. True: We may find that the system vendor suggests selecting parts of different schemas and constructing a pack and mix schema of your own. This is known as pragmatic approach, we need to understand of data loss through truncation and mapping. in this situation Metadata standard facilitate the interchange between system rather than describe a form of storage.
Question.5
While designing fact table it is being advised to use non-intelligent keys; but while designing summary table it is advised to use intelligent key. Why ?
Answer:
Unlike fact tables, summary tables are re-created on a regular basis, possibly every time new data is loaded. The purpose of the summary is to speed up queries, and reduce data joins with dimension data takes significant amounts of time.
Unlike fact tables, summary tables are re-created on a regular basis, possibly every time new data is loaded. The purpose of the summary is to speed up queries, and reduce data joins with dimension data takes significant amounts of time.
Question. 6
List some challenges (at least 5) in ETL testing.
Answer:
ETL: Stands for Extract-Transform-Load and a typical process of loading data from a source system to the actual data warehouse/other data integration projects.
ETL Testing: It is done to ensure that the data that has been loaded from a source to the destination after business transformation is accurate.
ETL Testing Challenges:
- Lack of proper flow of business information
- Existence of many ambiguous software requirements.
- Loss of data might be there during the ETL process
- Production sample data is not a true representation of all possible business processes.
- Existence of apparent trouble acquiring and building test data
- It requires SQL programming: This has become a major issue for the testers because they are manual testers and have limited SQL coding skills, thus making data testing very difficult.
Question.7
Given a SALES table with attributes(Product, Region, Sales), where each row represents sales of a product in a region. Using WINDOW functions, Write SQL queries that show
A. Sale of each Product in each region along with average sales over all regions, products in table
B. Sale of each product in each region along with average sales of the product among all regions.
Answer:
Window functions:
Window functions are similar to aggregate functions, but there is one important difference. When we use aggregate functions with the GROUP BY clause, we “lose” the individual rows. The function is performed on the rows as an entire group. This is not the case when we use window functions, we can generate a result set with some attributes of an individual row together with the results of the window function.
A. Sale of each Product in each region along with average sales over all regions, products in table
SELECT Product,
Region,
AVG(Sales) OVER(PARTITION BY Region) AS Average_Sales
FROM SALES;
B. Sale of each product in each region along with average sales of the product among all regions.
SELECT Product,
Region,
AVG(Sales) OVER(PARTITION BY Product) AS Average_Sales
FROM SALES;
Window functions:
Window functions are similar to aggregate functions, but there is one important difference. When we use aggregate functions with the GROUP BY clause, we “lose” the individual rows. The function is performed on the rows as an entire group. This is not the case when we use window functions, we can generate a result set with some attributes of an individual row together with the results of the window function.
A. Sale of each Product in each region along with average sales over all regions, products in table
SELECT Product,
Region,
AVG(Sales) OVER(PARTITION BY Region) AS Average_Sales
FROM SALES;
B. Sale of each product in each region along with average sales of the product among all regions.
SELECT Product,
Region,
AVG(Sales) OVER(PARTITION BY Product) AS Average_Sales
FROM SALES;
Question.8
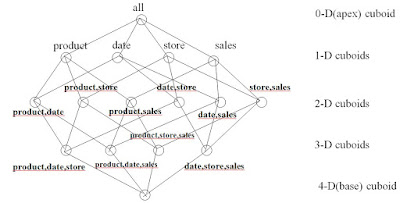
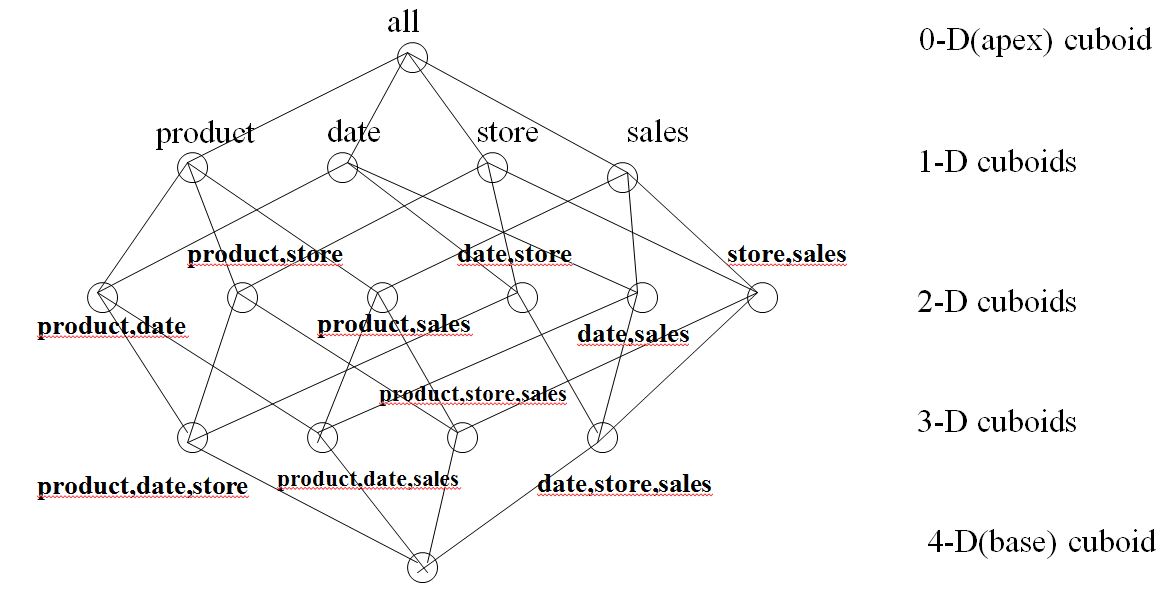
Consider a retail store data cube with dimensions Product, Date, and Store, and the measure attribute Sales
a. Draw the lattice of cuboids for this data cube without considering hierarchies.
b. Suppose that the dimensional attributes have the following hierarchies defined. How many cuboids would the data cube contain for this set of hierarchies?
Answer:
A.
Drawing a lattice of cuboids for the dimension:
B. Note: we are note sure about answer. Kindly post in comment box, if you have a correct answer.
Question.9
Consider the following relation on Stock Trading.
Record Id
|
Security Name
|
Trading Volume
|
Closing Price
|
Exchange
|
1
|
SBI
|
55075000
|
275.5
|
NSE
|
2
|
ICICI
|
23500000
|
285.25
|
BSE
|
3
|
Axis Bank
|
4567895
|
345.45
|
BSE
|
4
|
Bank of Baroda
|
32700
|
178
|
BSE
|
5
|
Yes Bank
|
670000
|
875.75
|
BSE
|
6
|
Kotak Mahindra Bank
|
50750000
|
945.7
|
NSE
|
7
|
HDFC Bank
|
45730000
|
955.9
|
BSE
|
8
|
Allahabad Bank
|
45000
|
156.3
|
BSE
|
9
|
Karnataka Bank
|
5600
|
145.3
|
BSE
|
10
|
Syndicate Bank
|
746000
|
135.7
|
NSE
|
11
|
Canara Bank
|
34670
|
245.6
|
NSE
|
12
|
Indusnd Bank
|
44550000
|
456.8
|
NSE
|
a. Construct a bitmap index for the attributes Exchange and Trading Volume for this table.
b. Indicate how these two bitmap-indices can be used to answer the query: Select all those tuples which traded in NSE and that have a trading volume of more than 30 million shares.
Answer:
a.
b.
NSE: (1 0 0 0 0 1 0 0 0 1 1 1)
TRADING VOLUME: (1 0 0 0 0 1 1 0 0 0 0 1)
We notice that the 1st, 6th and 12th bit in our question are traded at both the condition. We simply AND both bitmaps together.
Solution:
NSE: (1 0 0 0 0 1 0 0 0 1 1 1)
TdV: (1 0 0 0 0 1 1 0 0 0 0 1) AND
------------------------------------------
(1 0 0 0 0 1 0 0 0 0 0 1)
Given that the 1st, the 6th and the 12th bits of the resulting bitmap are set to 1, we can know that these stocks are traded in NSE and that have a trading volume of more than 30 million shares.
NOTE: BELOW IS THE EXAMPLE FOR THE SAME QUESTION, UNDERSTAND AND GET THE SOLUTIONS FOR THE SAME[THIS IS JUST FOR UNDERSTANDING].
Answer:
a.
Bitmap on Exchange
NSE
|
1
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
1
|
1
|
1
|
BSE
|
0
|
1
|
1
|
1
|
1
|
0
|
1
|
1
|
1
|
0
|
0
|
0
|
Bitmap on Trading Volume
55075000
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
23500000
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
4567895
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
32700
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
670000
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
50750000
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
45730000
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
45000
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
5600
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
746000
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
0
|
34670
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
0
|
44550000
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
b.
NSE: (1 0 0 0 0 1 0 0 0 1 1 1)
TRADING VOLUME: (1 0 0 0 0 1 1 0 0 0 0 1)
We notice that the 1st, 6th and 12th bit in our question are traded at both the condition. We simply AND both bitmaps together.
Solution:
NSE: (1 0 0 0 0 1 0 0 0 1 1 1)
TdV: (1 0 0 0 0 1 1 0 0 0 0 1) AND
------------------------------------------
(1 0 0 0 0 1 0 0 0 0 0 1)
Given that the 1st, the 6th and the 12th bits of the resulting bitmap are set to 1, we can know that these stocks are traded in NSE and that have a trading volume of more than 30 million shares.
NOTE: BELOW IS THE EXAMPLE FOR THE SAME QUESTION, UNDERSTAND AND GET THE SOLUTIONS FOR THE SAME[THIS IS JUST FOR UNDERSTANDING].
Bitmap Index:
Bitmap indexes are used by DBMSs to accelerate decision support queries. The main advantage of the bitmap index is that complex logical selection operations can be done very quickly by minimizing the search space before low cost Boolean operations like OR, AND, and NOT, before moving on to primary source data.
A Bitmap index: consists of one bitmap for each value that an attribute can take.
We will illustrate our discussion with a simple example about stock trading. Let us see the following table on stocks traded at different stock exchanges and consider the last column (Exchange).
Example:

We notice that stocks are traded at two different stock exchanges at NASDAQ and at NYSE. Indeed, the attribute Exchange has two distinct attribute values. In addition, we see that our stock examples include 12 different stocks, which are uniquely identified by their record ID given in the first column.
Simple bitmap for Stocks and their corresponding trading values:
NASDAQ: (1 0 0 0 0 1 0 0 0 1 1 1)
NYSE: (0 1 1 1 1 0 1 1 1 0 0 0)
We need two bitmaps because we have two distinct attribute values for the stock exchange. Each bitmap consists of 12 bit values since our example comprises 12 different stocks.
For instance, the last bit of the bitmap of NYSE is set to 0 because the last stock is not traded at NYSE. However, the second stock is traded at NYSE and, thus, the bit 2 is set to 1. In general, a bit is set to 1 if the stock is traded at the particular stock exchange, and it is set to 0 otherwise. Therefore, we have a straightforward way of describing the stock exchange by means of bitmaps.
For instance, the last bit of the bitmap of NYSE is set to 0 because the last stock is not traded at NYSE. However, the second stock is traded at NYSE and, thus, the bit 2 is set to 1. In general, a bit is set to 1 if the stock is traded at the particular stock exchange, and it is set to 0 otherwise. Therefore, we have a straightforward way of describing the stock exchange by means of bitmaps.
