
Question
This clustering approach initially assumes that each data instance represents a single cluster.
Select one:
a. expectation maximization
b. K-Means clustering
c. agglomerative clustering
d. conceptual clustering
The correct answer is:agglomerative clustering
Question
The correlation coefficient for two real-valued attributes is –0.85. What does this value tell you?
Select one:
a. The attributes are not linearly related.
b. As the value of one attribute decreases the value of the second attribute increases.
c. As the value of one attribute increases the value of the second attribute also increases.
d. The attributes show a linear relationship
The correct answer is: As the value of one attribute decreases the value of the second attribute increases.
Question
Time Complexity of k-means is given by
Select one:
a. O(mn)
b. O(tkn)
c. O(kn)
d. O(t2kn)
The correct answer is: O(tkn)
Question
Given a rule of the form IF X THEN Y, rule confidence is defined as the conditional probability that
Select one:
a. Y is false when X is known to be false.
b. Y is true when X is known to be true.
c. X is true when Y is known to be true
d. X is false when Y is known to be false.
The correct answer is: Y is true when X is known to be true.
Question
Chameleon is
Select one:
a. Density based clustering algorithm
b. Partitioning based algorithm
c. Model based algorithm
d. Hierarchical clustering algorithm
The correct answer is: Hierarchical clustering algorithm
Question
In _________ clusterings, points may belong to multiple clusters
Select one:
a. Non exclusivce
b. Partial
c. Fuzzy
d. Exclusive
The correct answer is: Fuzzy
Question
Find odd man out
Select one:
a. DBSCAN
b. K mean
c. PAM
d. K medoid
The correct answer is: DBSCAN
Question
Which statement is true about the K-Means algorithm?
Select one:
a. The output attribute must be cateogrical.
b. All attribute values must be categorical.
c. All attributes must be numeric
d. Attribute values may be either categorical or numeric
The correct answer is: All attributes must be numeric
Question
This data transformation technique works well when minimum and maximum values for a real-valued attribute are known.
Select one:
a. z-score normalization
b. min-max normalization
c. logarithmic normalization
d. decimal scaling
The correct answer is: min-max normalization
Question
The number of iterations in apriori ___________
Select one:
a. increases with the size of the data
b. decreases with the increase in size of the data
c. increases with the size of the maximum frequent set
d. decreases with increase in size of the maximum frequent set
The correct answer is: increases with the size of the maximum frequent set
Question
Which of the following are interestingness measures for association rules?
Select one:
a. recall
b. lift
c. accuracy
d. compactness
The correct answer is: lift
Question
Which one of the following is not a major strength of the neural network approach?
Select one:
a. Neural network learning algorithms are guaranteed to converge to an optimal solution
b. Neural networks work well with datasets containing noisy data.
c. Neural networks can be used for both supervised learning and unsupervised clustering
d. Neural networks can be used for applications that require a time element to be included in the data
The correct answer is: Neural network learning algorithms are guaranteed to converge to an optimal solution
Question
Given a frequent itemset L, If |L| = k, then there are
Select one:
a. 2k - 1 candidate association rules
b. 2k candidate association rules
c. 2k - 2 candidate association rules
d. 2k -2 candidate association rules
The correct answer is: 2k -2 candidate association rules
Question
. _________ is an example for case based-learning
Select one:
a. Decision trees
b. Neural networks
c. Genetic algorithm
d. K-nearest neighbor
The correct answer is: K-nearest neighbor
Question
The average positive difference between computed and desired outcome values.
Select one:
a. mean positive error
b. mean squared error
c. mean absolute error
d. root mean squared error
The correct answer is: mean absolute error
Question
Frequent item sets is
Select one:
a. Superset of only closed frequent item sets
b. Superset of only maximal frequent item sets
c. Subset of maximal frequent item sets
d. Superset of both closed frequent item sets and maximal frequent item sets
The correct answer is: Superset of both closed frequent item sets and maximal frequent item sets
Question
1. Assume that we have a dataset containing information about 200 individuals. A supervised data mining session has discovered the following rule:
IF age < 30 & credit card insurance = yes THEN life insurance = yes
Rule Accuracy: 70% and Rule Coverage: 63%
How many individuals in the class life insurance= no have credit card insurance and are less than 30 years old?
Select one:
a. 63
b. 30
c. 38
d. 70
The correct answer is: 38
Question
Use the three-class confusion matrix below to answer percent of the instances were correctly classified?
Computed Decision | |||
Class 1
|
Class 2
|
Class 3
| |
Class 1
|
10
|
5
|
3
|
Class 2
|
5
|
15
|
3
|
Class 3
|
2
|
2
|
5
|
Select one:
a. 60
b. 40
c. 50
d. 30
The correct answer is: 60
Which of the following is cluster analysis?
Select one:
a. Simple segmentation
b. Grouping similar objects
c. Labeled classification
d. Query results grouping
The correct answer is: Grouping similar objects
Question
A good clustering method will produce high quality clusters with
Select one:
a. high inter class similarity
b. low intra class similarity
c. high intra class similarity
d. no inter class similarity
The correct answer is: high intra class similarity
Question
Which two parameters are needed for DBSCAN
Select one:
a. Min threshold
b. Min points and eps
c. Min sup and min confidence
d. Number of centroids
The correct answer is: Min points and eps
Question
Which statement is true about neural network and linear regression models?
Select one:
a. Both techniques build models whose output is determined by a linear sum of weighted input attribute values.
b. The output of both models is a categorical attribute value.
c. Both models require numeric attributes to range between 0 and 1.
d. Both models require input attributes to be numeric.
The correct answer is: Both models require input attributes to be numeric.
Question
In Apriori algorithm, if 1 item-sets are 100, then the number of candidate 2 item-sets are
Select one:
a. 100
b. 4950
c. 200
d. 5000
The correct answer is: 4950
Question
Significant Bottleneck in the Apriori algorithm is
Select one:
a. Finding frequent itemsets
b. Pruning
c. Candidate generation
d. Number of iterations
The correct answer is: Candidate generation
Question
The concept of core, border and noise points fall into this category?
Select one:
a. DENCLUE
b. Subspace clustering
c. Grid based
d. DBSCAN
The correct answer is: DBSCAN
Question
The correlation coefficient for two real-valued attributes is –0.85. What does this value tell you?
Select one:
a. The attributes show a linear relationship
b. The attributes are not linearly related.
c. As the value of one attribute increases the value of the second attribute also increases.
d. As the value of one attribute decreases the value of the second attribute increases.
The correct answer is: As the value of one attribute decreases the value of the second attribute increases.
Question
Machine learning techniques differ from statistical techniques in that machine learning methods
Select one:
a. are better able to deal with missing and noisy data
b. typically assume an underlying distribution for the data
c. have trouble with large-sized datasets
d. are not able to explain their behavior.
The correct answer is: are better able to deal with missing and noisy data
Question
The probability of a hypothesis before the presentation of evidence.
Select one:
a. a priori
b. posterior
c. conditional
d. subjective
The correct answer is: a priori
Question
KDD represents extraction of
Select one:
a. data
b. knowledge
c. rules
d. model
The correct answer is: knowledge
Question
Which statement about outliers is true?
Select one:
a. Outliers should be part of the training dataset but should not be present in the test data.
b. Outliers should be identified and removed from a dataset.
c. The nature of the problem determines how outliers are used
d. Outliers should be part of the test dataset but should not be present in the training data.
The correct answer is: The nature of the problem determines how outliers are used
Question
The most general form of distance is
Select one:
a. Manhattan
b. Eucledian
c. Mean
d. Minkowski
The correct answer is: Minkowski
Question
Arbitrary shaped clusters can be found by using
Select one:
a. Density methods
b. Partitional methods
c. Hierarchical methods
d. Agglomerative
The correct answer is: Density methods
Question
Which Association Rule would you prefer
Select one:
a. High support and medium confidence
b. High support and low confidence
c. Low support and high confidence
d. Low support and low confidence
The correct answer is: Low support and high confidence
Question
With Bayes theorem the probability of hypothesis H¾ specified by P(H) ¾ is referred to as
Select one:
a. a conditional probability
b. an a priori probability
c. a bidirectional probability
d. a posterior probability
The correct answer is: an a priori probability
Question
In a Rule based classifier, If there is a rule for each combination of attribute values, what do you called that rule set R
Select one:
a. Exhaustive
b. Inclusive
c. Comprehensive
d. Mutually exclusive
The correct answer is: Exhaustive
Question
The apriori property means
Select one:
a. If a set cannot pass a test, its supersets will also fail the same test
b. To decrease the efficiency, do level-wise generation of frequent item sets
c. To improve the efficiency, do level-wise generation of frequent item sets
d. If a set can pass a test, its supersets will fail the same test
The correct answer is: If a set cannot pass a test, its supersets will also fail the same test
Question
Clustering is ___________ and is example of ____________learning
Select one:
a. Predictive and supervised
b. Predictive and unsupervised
c. Descriptive and supervised
d. Descriptive and unsupervised
The correct answer is: Descriptive and unsupervised
Question
The probability that a person owns a sports car given that they subscribe to automotive magazine is 40%. We also know that 3% of the adult population subscribes to automotive magazine. The probability of a person owning a sports car given that they don’t subscribe to automotive magazine is 30%. Use this information to compute the probability that a person subscribes to automotive magazine given that they own a sports car
Select one:
a. 0.0368
b. 0.0396
c. 0.0389
d. 0.0398
The correct answer is: 0.0396
Question
Simple regression assumes a __________ relationship between the input attribute and output attribute.
Select one:
a. quadratic
b. inverse
c. linear
d. reciprocal
The correct answer is: linear
Question
Which of the following algorithm comes under the classification
Select one:
a. Apriori
b. Brute force
c. DBSCAN
d. K-nearest neighbor
The correct answer is: K-nearest neighbor
Question
Hierarchical agglomerative clustering is typically visualized as?
Select one:
a. Dendrogram
b. Binary trees
c. Block diagram
d. Graph
The correct answer is: Dendrogram
Question
The _______ step eliminates the extensions of (k-1)-itemsets which are not found to be frequent,from being considered for counting support
Select one:
a. Partitioning
b. Candidate generation
c. Itemset eliminations
d. Pruning
The correct answer is: Pruning
Question
To determine association rules from frequent item sets
Select one:
a. Only minimum confidence needed
b. Neither support not confidence needed
c. Both minimum support and confidence are needed
d. Minimum support is needed
The correct answer is: Only minimum confidence needed
Question
What is the final resultant cluster size in Divisive algorithm, which is one of the hierarchical clustering approaches?
Select one:
a. Zero
b. Three
c. singleton
d. Two
The correct answer is: singleton
Question
If {A,B,C,D} is a frequent itemset, candidate rules which is not possible is
Select one:
a. C --> A
b. D -->ABCD
c. A --> BC
d. B --> ADC
The correct answer is: D -->ABCD
Question
Which Association Rule would you prefer
Select one:
a. High support and low confidence
b. Low support and high confidence
c. Low support and low confidence
d. High support and medium confidence
The correct answer is: Low support and high confidence
Question
The probability that a person owns a sports car given that they subscribe to automotive magazine is 40%. We also know that 3% of the adult population subscribes to automotive magazine. The probability of a person owning a sports car given that they don’t subscribe to automotive magazine is 30%. Use this information to compute the probability that a person subscribes to automotive magazine given that they own a sports car
Select one:
a. 0.0398
b. 0.0389
c. 0.0368
d. 0.0396
The correct answer is: 0.0396
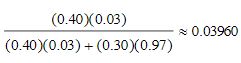
Question
This clustering algorithm terminates when mean values computed for the current iteration of the algorithm are identical to the computed mean values for the previous iteration
Select one:
a. conceptual clustering
b. K-Means clustering
c. expectation maximization
d. agglomerative clustering
The correct answer is: K-Means clustering
Question
The distance between two points calculated using Pythagoras theorem is
Select one:
a. Supremum distance
b. Eucledian distance
c. Linear distance
d. Manhattan Distance
The correct answer is: Eucledian distance
Question
Classification rules are extracted from _____________
Select one:
a. decision tree
b. root node
c. branches
d. siblings
The correct answer is: decision tree
Question
What does K refers in the K-Means algorithm which is a non-hierarchical clustering approach?
Select one:
a.Fixed value
b.No of iterations
c.Complexity
d.number of clusters
The correct answer is: number of clusters
Question
Which is not part of the categories of clustering methods?
Select one:
a.Hierarchical methods
b.Density based methods
c.Partitioning methods
d.Rule-based methods
The correct answer is: Rule-based methods
Question
Given desired class C and population P, lift is defined as
Select one:
a.the probability of class C given population P divided by the probability of C given a sample taken from the population
b.the probability of class C given a sample taken from population P.
c.the probability of class C given a sample taken from population P divided by the probability of C within the entire population P.
d.the probability of population P given a sample taken from P
The correct answer is: the probability of class C given a sample taken from population P divided by the probability of C within the entire population P
Question
If an item set ‘XYZ’ is a frequent item set, then all subsets of that frequent item set are
Select one:
a. Frequent
b. Not frequent
c. Can not say
d. Undefined
The correct answer is: Frequent
Question
With Bayes theorem the probability of hypothesis H¾ specified by P(H) ¾ is referred to as
Select one:
a. a posterior probability
b. a bidirectional probability
c. a conditional probability
d. an a priori probability
The correct answer is: an a priori probability
This clustering algorithm terminates when mean values computed for the current iteration of the algorithm are identical to the computed mean values for the previous iteration
Select one:
a. conceptual clustering
b. K-Means clustering
c. expectation maximization
d. agglomerative clustering
The correct answer is: K-Means clustering
Question
The distance between two points calculated using Pythagoras theorem is
Select one:
a. Supremum distance
b. Eucledian distance
c. Linear distance
d. Manhattan Distance
The correct answer is: Eucledian distance
Question
Classification rules are extracted from _____________
Select one:
a. decision tree
b. root node
c. branches
d. siblings
The correct answer is: decision tree
Question
What does K refers in the K-Means algorithm which is a non-hierarchical clustering approach?
Select one:
a.Fixed value
b.No of iterations
c.Complexity
d.number of clusters
The correct answer is: number of clusters
Question
Which is not part of the categories of clustering methods?
Select one:
a.Hierarchical methods
b.Density based methods
c.Partitioning methods
d.Rule-based methods
The correct answer is: Rule-based methods
Question
Given desired class C and population P, lift is defined as
Select one:
a.the probability of class C given population P divided by the probability of C given a sample taken from the population
b.the probability of class C given a sample taken from population P.
c.the probability of class C given a sample taken from population P divided by the probability of C within the entire population P.
d.the probability of population P given a sample taken from P
The correct answer is: the probability of class C given a sample taken from population P divided by the probability of C within the entire population P
Question
Select one:
a. Frequent
b. Not frequent
c. Can not say
d. Undefined
The correct answer is: Frequent
Question
With Bayes theorem the probability of hypothesis H¾ specified by P(H) ¾ is referred to as
Select one:
a. a posterior probability
b. a bidirectional probability
c. a conditional probability
d. an a priori probability
The correct answer is: an a priori probability

What is the answer for
ReplyDelete1. This clustering approach initially assumes that each data instance represents a single cluster.
2. Given desired class C and population P, lift is defined as
3. This clustering algorithm terminates when mean values computed for the current iteration of the algorithm are identical to the computed mean values for the previous iteration
4.What does K refers in the K-Means algorithm which is a non-hierarchical clustering approach?
1. Agglomeration clustering.
Delete2. The probability of class C given a sample taken from population P divided by the probability of C within the entire population P.
3. K- means clustering
Ans : K-means clustering
DeleteKindly answer the below aswel.
ReplyDeleteWhat is not part of the categories of clustering methods?
Rule-based methods
DeleteAnswer this also .???
ReplyDeleteQ-Which is not part of the categories of clustering methods?
Select one:
a. Partitioning methods
b.
Rule-based methods
c. Hierarchical methods
d. Density based methods
Rule-based methods
DeleteRule-based methods
DeleteWhat does K refers in the K-Means algorithm which is a non-hierarchical clustering approach?
ReplyDeleteSelect one:
a. Complexity
b. Fixed value
c.
number of clusters
d. No of iterations
number of clusters
DeleteIf an item set ‘XYZ’ is a frequent item set, then all subsets of that frequent item set are
ReplyDeleteSelect one:
a. Frequent
b. Can not say
c. Undefined
d. Not frequent
Kundar Sir, class mei padai kiya karo
Deletehahahha.. pahadi .. tumhi ans bata diya kro
ReplyDeleteGiven desired class c and population people, lift is defined as
ReplyDeleteBy show, the "head" of a rundown is the hub having no past hub. What's more, the "tail", the one that has no next hub. ExcelR Data Science Courses
ReplyDeleteWow! Such an amazing and helpful post this is. I really really love it. It's so good and so awesome. I am just amazed. I hope that you continue to do your work like this in the future also underground mining equipment
ReplyDeleteI am just commenting to let you know of the perfect experience my wife's princess encountered studying your web site. She picked up numerous details, most notably what it's like to have an ideal helping character to have many more very easily gain knowledge of selected advanced subject matter. You undoubtedly exceeded our own expectations. Thanks for offering such effective, healthy, explanatory and in addition fun thoughts on this topic to Gloria. data science from scratch
ReplyDeleteInformative blog and knowledgeable content. Thanks for sharing this awesome blog with us. If you want to learn data science then follow the below link.
ReplyDeleteBest Data Science Course in Hyderabad